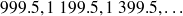Quelques réflexions sur le groupement en classes
Le groupement en classes est une opération qui présente a priori une certaine part de subjectivité tant au niveau du nombre de classes choisi que de leur longueur ou de la définition de leurs bornes.
Choix du nombre de classes
Le choix du nombre de classes est souvent guidé par le bon sens et la pratique. Il dépend aussi des objectifs du groupement. S'il s'agit seulement de se faire une idée sur la répartition générale des observations, on peut effectuer ce choix de manière relativement souple. Il ne faut évidemment pas trop peu de classes ; un nombre élevé est aussi critiquable (surtout si
 n'est pas grand). Rappelons que notre objectif est de « montrer » la distribution observée.
n'est pas grand). Rappelons que notre objectif est de « montrer » la distribution observée.
Exemple : Tailles (suite)
Voici, à titre d'illustration, la superposition de l'histogramme basé sur 5 classes de même longueur et de ceux construits respectivement avec 3 classes de longueur 17 et 17 classes de longueur 3.
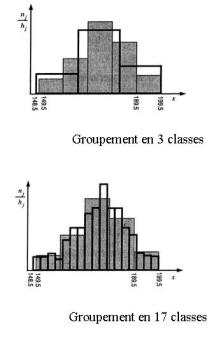 Groupements en 3 classes et en 17 classes de la distribution des tailles | Le groupement en 3 classes résume de manière très grossière la distribution des 175 tailles. Le groupement en 17 classes fournit une synthèse beaucoup plus fine (trop fine ?) de cette distribution. A vous de définir le choix que vous feriez ! |
Il existe dans la littérature statistique des règles empiriques pour aider le praticien à choisir le nombre de classes. Ainsi, par exemple, la règle de Sturges conseille de prendre un nombre
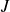 de classes proche de la valeur
de classes proche de la valeur
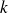 fournie par l'équation
fournie par l'équation
Il n'y a cependant aucune obligation à suivre ce genre de règle.
Choix de la longueur des classes
Dans l'exemple relatif aux tailles d'étudiants, nous avons choisi 5 classes de même longueur
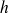 égale à
égale à
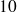 cm. Nous aurions pu aussi retenir un nombre de classes différent, par exemple 6 classes de longueur
cm. Nous aurions pu aussi retenir un nombre de classes différent, par exemple 6 classes de longueur
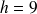 cm ou encore 7 classes de longueur
cm ou encore 7 classes de longueur
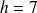 cm.
cm.
Le fait de construire des classes de même longueur peut simplifier l'analyse de la D.G.1. Il est toutefois parfois préférable d'utiliser des classes de longueurs différentes. Il en est ainsi, par exemple, pour la distribution de salaires (exprimés en centaines d'euros) présentée dans la figure ci-dessous.
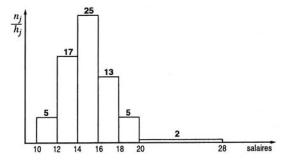
La dernière classe a été choisie quatre fois plus longue que les précédentes de manière à pouvoir y inclure des observations élevées sans devoir créer des classes intermédiaires vides.
Certaines méthodes de traitement statistique préconisent aussi de construire des classes de même effectif. Nous ne traiterons pas ce cas ici.
En outre, lorsqu'on analyse des séries contenant des valeurs qui sont très différentes de la majorité des autres observations, on voit parfois apparaître des classes ouvertes. Ainsi, la dernière classe de la D.G.1 des salaires considérée dans la figure ci-dessus aurait pu être remplacée par la classe ouverte contenant « l'ensemble des salaires supérieurs à 2 000 euros ». Il n'est cependant plus possible de représenter alors graphiquement la partie de l'histogramme correspondant à une telle classe ; le fait que l'on ne puisse définir de centre ou d'autre valeur représentative naturelle pour une classe ouverte pose également problème pour le calcul de certaines mesures de position, de dispersion ou de forme, comme nous le verrons plus loin.
Choix des bornes des classes
Il n'est pas toujours pertinent de construire des bornes de classe comportant une décimale de plus que les observations. C'est le cas de la distribution des salaires ci-dessus pour laquelle les bornes des classes correspondent à des valeurs observables :
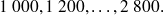 Dans ce cas, les classes correspondent aux intervalles
Dans ce cas, les classes correspondent aux intervalles
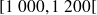 (c'est-à-dire
(c'est-à-dire
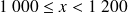 ),
),
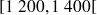 (c'est-à-dire
(c'est-à-dire
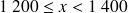 ), etc. La longueur des classes est telle qu'il serait absurde de faire intervenir des bornes exactes telles que
), etc. La longueur des classes est telle qu'il serait absurde de faire intervenir des bornes exactes telles que