Distribution groupée (D.G.1) des effectifs et des fréquences
Considérons ici la situation où la variable
 étudiée est quantitative (d'intervalles ou de rapports).
étudiée est quantitative (d'intervalles ou de rapports).
Si la précision des mesures effectuées est fine et que le nombre
 d'observations est grand, il peut arriver que le nombre de valeurs distinctes observées soit relativement élevé. La D.O.1 qui en découle peut alors présenter :
d'observations est grand, il peut arriver que le nombre de valeurs distinctes observées soit relativement élevé. La D.O.1 qui en découle peut alors présenter :
un grand nombre de lignes dans le tableau des effectifs ;
de nombreux effectifs de faible amplitude.
Cette situation ne permet pas de dégager facilement les caractéristiques essentielles de la distribution observée.
Une solution à ce problème consiste à adopter une approche plus globale des données en réalisant un groupement de ces dernières, c'est-à-dire en rassemblant dans une même catégorie (qui sera appelée une classe) des valeurs observées relativement proches les unes des autres.
Un exemple en guise d'introduction
Exemple : Tailles
Une étude réalisée auprès de 175 étudiants d'une université pratiquant le volley comportait une question sur leur taille. La série statistique ci-dessous présente ainsi les tailles de ces étudiants, arrondies au centimètre le plus proche et saisies dans l'ordre du dépouillement de l'enquête.
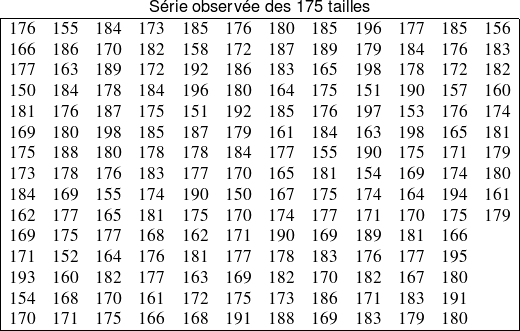
Nous pouvons proposer une toute première réorganisation des données en construisant la série statistique ordonnée, c'est-à-dire en présentant les 175 tailles par ordre croissant.

Les tailles des étudiants varient donc de 150 cm à 198 cm.
Nous pouvons ensuite construire aisément la D.O.1 des effectifs correspondant à cette série statistique ordonnée et la représenter graphiquement à l'aide du diagramme en bâtons. Ce dernier est présenté ci-dessous.
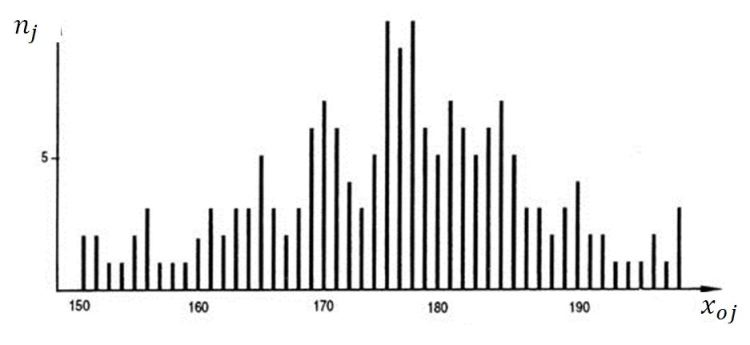
Ce diagramme en bâtons apparaît assez « chahuté ». On voit bien sûr apparaître des effectifs plus importants au centre du graphique, mais la comparaison des bâtons situés les uns à côté des autres n'est pas très instructive ; il n'est en tout cas pas simple de dégager les caractéristiques de cette distribution !
Le groupement des données en classes
Puisque associer son effectif à chaque valeur distincte observée (autrement dit considérer la D.O.1) ne permet pas de dégager efficacement l'information pertinente contenue dans les données, nous allons adopter une approche plus globale de ces dernières en considérant des classes de valeurs observées. En d'autres termes, nous allons opérer un regroupement des données en classes.
Exemple : Tailles (suite)
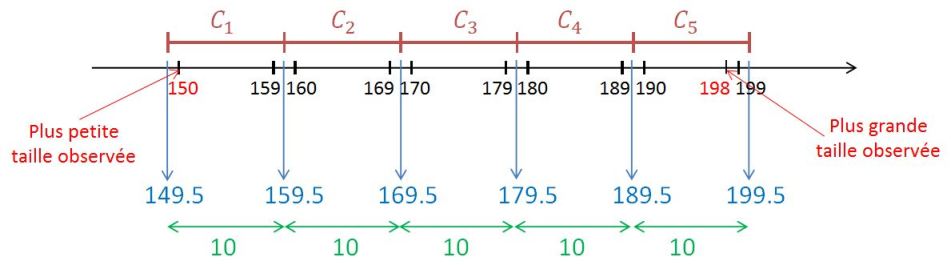
Nous pouvons par exemple considérer les 5 classes de tailles suivantes :
la classe 1 contient les tailles allant de 150 à 159 cm ;
la classe 2 contient les tailles allant de 160 à 169 cm ;
la classe 3 contient les tailles allant de 170 à 179 cm ;
la classe 4 contient les tailles allant de 180 à 189 cm ;
la classe 5 contient les tailles allant de 190 à 199 cm.
Ces 5 classes partitionnent bien l'ensemble des tailles observées sur les 175 étudiants :
la première classe contient la plus petite taille observée (150 cm) et la dernière classe (la 5e) contient la plus grande taille observée (198 cm) ;
chacune des tailles observées peut être classée dans une et une seule des 5 classes proposées.
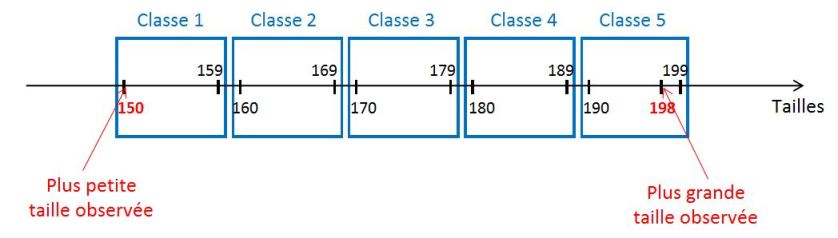
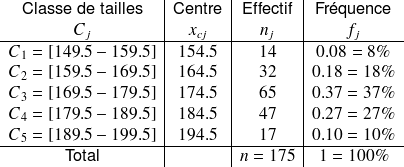
Une fois les classes construites, nous devons associer à chacune d'elle son effectif, c'est-à-dire le nombre d'étudiants ayant une taille comprise dans la classe. En regardant la série statistique ordonnée, on vérifie aisément que 14 étudiants mesurent entre 150 et 159 cm (l'effectif de la classe 1 est donc égal à 14), 32 étudiants mesurent entre 160 et 169 cm (l'effectif de la classe 2 est donc égal à 32), etc. On obtient ainsi la distribution groupée (D.G.1) des tailles suivante :

Le groupement des données en classes occasionne la perte d'une certaine quantité d'information sur les données : nous savons par exemple que 14 étudiants mesurent entre 150 et 159 cm, mais la D.G.1 ne nous indique pas quelles sont exactement les tailles de ces étudiants ; pour avoir cette information, il faut obligatoirement retourner à la série statistique ordonnée de départ.
En revanche, il permet de dégager plus facilement les principales caractéristiques des observations : la distribution groupée que nous avons déterminée met en évidence le fait que c'est la classe des tailles de 170 à 179 cm qui contient le plus grand nombre d'étudiants ; le nombre d'étudiants de « petites » tailles (de 150 à 159 cm) diffère peu du nombre d'étudiants de « grandes » tailles (de 190 à 199 cm).
La construction des classes
Plusieurs méthodes permettent d'opérer de tels regroupements des données en classes.
La démarche empirique
Les classes peuvent être définies en nous basant sur notre « bon sens » ou sur la connaissance que nous avons du « comportement » de la variable étudiée.
Dans certains cas aussi, leur construction se fonde sur des critères liés aux techniques d'analyse qui seront appliquées aux données après leur regroupement : on peut ainsi, par exemple, être amené à construire les classes de telle sorte qu'elles contiennent toutes approximativement le même nombre d'observations.
Le diagramme en tiges et feuilles
Il peut être utile, dans certaines situations, de se laisser guider par une première analyse exploratoire des données basée sur le diagramme en tiges et feuilles (encore appelé diagramme en branches et rameaux) proposé par Tukey. Ce diagramme découle d'un simple décompte des données. Présentons-le à partir de notre exemple.
Exemple : Tailles (suite)
Les nombres contenus dans la série statistique observée possèdent tous trois chiffres. Les deux premiers d'entre eux sont identiques pour plusieurs valeurs, par exemple 150, 151, 152, ..., 158. On peut donc classer les observations de la série sur la base de cette propriété commune (les observations ayant les deux premiers chiffres en commun feront partie de la même tige) et différencier les observations d'une même tige sur la base du troisième chiffre (que l'on dénomme la feuille).
C'est ainsi, par exemple, que la première observation 176 se situe sur la tige 17 et est représentée par la première feuille égale à 6. La deuxième observation 166 est attachée à la tige 16 et est représentée par la feuille 6, et ainsi de suite. En procédant de la sorte pour toutes les observations de la série statistique observée, on obtient le diagramme en tiges et feuilles ci-dessous, dans lequel on indique les tiges à gauche de la barre verticale et les feuilles à leur droite.

Cette construction nous a amenés à grouper les observations dans des classes (les tiges) qui découlent de notre système décimal de notation : 150 à 159 ; 160 à 169 ; 170 à 179 ; 180 à 189 ; 190 à 199.
Le diagramme en tiges et feuilles nous permet de calculer aisément les nombres de feuilles par tige (les nombres d'observations par classe) qui valent respectivement 14, 32, 65, 47 et 17.
Remarquons que nous pouvons encore mieux nous rendre compte de la répartition des feuilles sur chaque tige en ordonnant les valeurs observées, comme dans la figure ci-dessous.

Conseil :
Le diagramme en tiges et feuilles peut nous guider dans la détermination des classes. On peut associer une classe à chaque tige, comme dans notre exemple ; mais on peut aussi, dans le cas où une tige porte un grand nombre de feuilles, lui associer deux ou trois classes de manière à ce que le groupement des données mette mieux en évidence les principales caractéristiques des données observées.
La démarche en trois étapes
De manière générale, la démarche de construction des classes peut être décomposée en trois étapes interdépendantes.
Méthode : Première étape
On doit d'abord choisir le nombre de classes que l'on désire construire.
Ce nombre sera désigné par
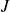 ; il est généralement compris entre 5 et 20 et est bien évidemment fonction du nombre
d'observations dans la série statistique de départ (si la série n'est constituée que d'une centaine d'observations, par exemple, il serait absurde de vouloir la partitionner en 20 classes ; à l'inverse, si la série compte un millier d'observations, par exemple, ne vouloir construire que 5 classes conduirait vraisemblablement à une synthèse trop globale de la distribution observée).
; il est généralement compris entre 5 et 20 et est bien évidemment fonction du nombre
d'observations dans la série statistique de départ (si la série n'est constituée que d'une centaine d'observations, par exemple, il serait absurde de vouloir la partitionner en 20 classes ; à l'inverse, si la série compte un millier d'observations, par exemple, ne vouloir construire que 5 classes conduirait vraisemblablement à une synthèse trop globale de la distribution observée).
Les
classes à construire seront désignées par
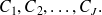
Exemple : Tailles (suite)
Etant donné la taille de la série statistique observée (
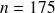 ) et ce que nous avons déjà pu constater de la distribution observée des tailles, il semble raisonnable de vouloir construire 5 classes. Nous choisissons donc
) et ce que nous avons déjà pu constater de la distribution observée des tailles, il semble raisonnable de vouloir construire 5 classes. Nous choisissons donc
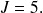
Méthode : Deuxième étape
Une fois le nombre de classes choisi, il faut déterminer la longueur des classes.
Dans un premier temps, on prend les
classes de même longueur (quitte à regrouper des classes ou, au contraire, à en redécouper certaines dans la suite de la procédure de la construction de la D.G.1 ; voir plus loin) ; la longueur commune des classes sera désignée par
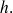
La détermination de la valeur de
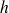 se fait de la manière suivante. On obtient tout d'abord une valeur approchée de
en calculant
se fait de la manière suivante. On obtient tout d'abord une valeur approchée de
en calculant
La valeur exacte de
s'obtient alors en arrondissant par excès la valeur approchée que l'on vient d'obtenir (
s'exprime généralement avec la même précision que les observations, c'est-à-dire avec autant de décimales que les observations elles-mêmes).
Exemple : Tailles (suite)
La valeur approchée de
est donnée par
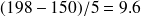 (cm). Il s'ensuit que
(cm). Il s'ensuit que
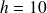 (cm).
(cm).
Chacune des 5 classes aura donc une longueur de 10 cm.
Méthode : Troisième étape
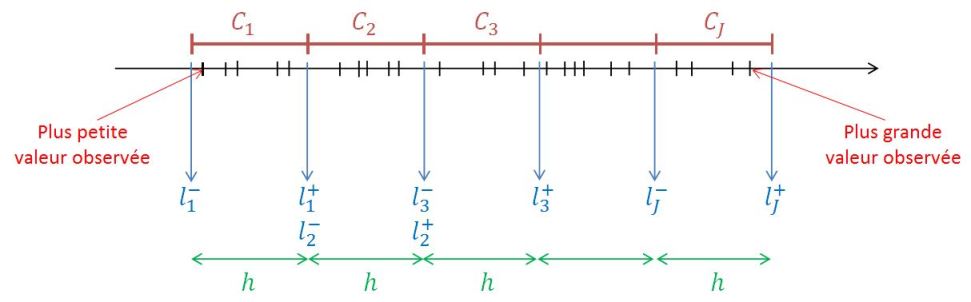
La troisième étape consiste à choisir la borne (ou limite) inférieure de la première classe ; on en déduira aisément les bornes de chacune des
classes, puisqu'on connaît la longueur des classes.
Désignons par
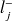 la borne (ou limite) inférieure de la classe
la borne (ou limite) inférieure de la classe
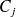 et par
et par
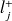 sa borne (ou limite) supérieure :
sa borne (ou limite) supérieure :
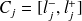
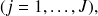 avec
avec
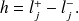
On peut définir les classes par la plus petite et la plus grande valeur observable qu'elles peuvent contenir. Toutefois, il est souvent plus judicieux de définir les classes par des bornes (ou limites) de classe communes de telle sorte que les classes soient contiguës :
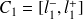 ,
,
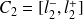 , ..., avec
, ..., avec
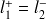 ,
,
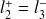 , ... Pour éviter tout problème de définition des classes, il suffit alors de faire en sorte que les bornes des classes ne puissent pas correspondre à une observation (en effet, si une observation coïncidait avec une limite de classe,
par exemple, cette observation appartiendrait à la fois à la classe
et à la classe
, ... Pour éviter tout problème de définition des classes, il suffit alors de faire en sorte que les bornes des classes ne puissent pas correspondre à une observation (en effet, si une observation coïncidait avec une limite de classe,
par exemple, cette observation appartiendrait à la fois à la classe
et à la classe
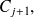 ce qui n'est bien sûr pas acceptable) ; cette condition est automatiquement satisfaite si l'on exprime les bornes des classes avec une décimale de plus que les observations elles-mêmes.
ce qui n'est bien sûr pas acceptable) ; cette condition est automatiquement satisfaite si l'on exprime les bornes des classes avec une décimale de plus que les observations elles-mêmes.
Exemple : Tailles (suite)
Les tailles observées sont des valeurs entières. Pour que les bornes des classes ne puissent coïncider avec aucune des tailles observées, nous allons tout simplement les définir sous la forme de nombres possédant une décimale.
La première classe doit contenir la plus petite taille observée (150 cm) ; il suffit dès lors de prendre la borne inférieure
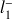 de la première classe égale à 149.5 cm. Puisque les classes doivent être de longueur égale à 10 cm, on a alors les 5 classes suivantes :
de la première classe égale à 149.5 cm. Puisque les classes doivent être de longueur égale à 10 cm, on a alors les 5 classes suivantes :
classe
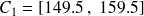 : classe contenant les tailles observées de
: classe contenant les tailles observées de
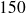 à
à
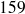 cm ;
cm ; classe
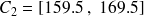 : classe contenant les tailles observées de
: classe contenant les tailles observées de
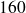 à
à
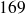 cm ;
cm ; classe
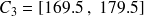 : classe contenant les tailles observées de
: classe contenant les tailles observées de
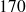 à
à
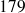 cm ;
cm ; classe
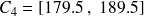 : classe contenant les tailles observées de
: classe contenant les tailles observées de
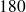 à
à
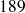 cm ;
cm ; classe
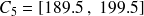 : classe contenant les tailles observées de
: classe contenant les tailles observées de
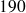 à
à
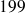 cm.
cm.
Remarque :
Il arrive parfois que l'on se rende compte, dans la suite de la détermination de la distribution groupée, que l'une ou l'autre classe contient un nombre d'observations fort élevé ou, au contraire, un très faible nombre d'observations. On peut alors être amené à couper une classe en deux nouvelles classes ou, au contraire, à regrouper deux classes contiguës pour n'en faire qu'une seule. Dans ce cas, on se retrouve avec des classes qui n'ont plus toutes les mêmes longueurs. On désignera alors, de façon générale, la longueur de la classe
par
D.G.1 des effectifs et des fréquences
Définition :
La D.G.1 est caractérisée par les éléments suivants :
les
classes
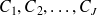 ;
; chaque classe
est définie par sa borne (ou limite) inférieure
et sa borne (ou limite) supérieure
; sa longueur est donnée par
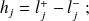
chaque classe
possède une valeur représentative privilégiée : son centre
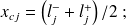
à chaque classe
sont associés un effectif de classe
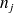 (égal au nombre d'observations de la série statistique de départ qui appartiennent à la classe
) ainsi qu'une fréquence de classe
(égal au nombre d'observations de la série statistique de départ qui appartiennent à la classe
) ainsi qu'une fréquence de classe
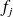 (correspondant à la proportion d'observations de la série statistique de départ qui appartiennent à la classe
).
(correspondant à la proportion d'observations de la série statistique de départ qui appartiennent à la classe
).

Exemple : Tailles (suite)
La D.G.1 des tailles que nous avons construite est présentée dans le tableau ci-dessous :