

Distribution observée (D.O.1) des effectifs et des fréquences
Exemple : Femmes
Une enquête réalisée aux USA en 1988 auprès de 92 901 femmes de 18 ans ou plus s'est notamment intéressée à l'état civil (défini selon les quatre modalités suivantes : célibataire, mariée, veuve, divorcée) de ces femmes.
Comment présenter les données relatives à cette variable « état civil » ?
Distribution observée (univariée) – D.O.1 – des effectifs
Donner la série statistique observée, c'est-à-dire la liste associant son état civil à chacune des 92 901 femmes (liste des 92 901 observations), n'est vraiment pas la bonne manière de procéder. Il est bien plus naturel et pratique d'indiquer le nombre de fois que chacune des modalités de la variable « état civil » a été observée, c'est-à-dire, en d'autres termes, d'associer à chaque modalité de la variable l'effectif qui lui correspond. Ceci revient à construire le tableau de la distribution observée (univariée) – D.O.1 – des effectifs.
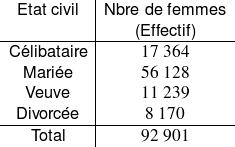
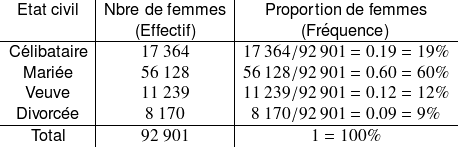
Ce tableau nous indique clairement que, parmi les
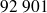 femmes interrogées,
femmes interrogées,
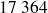 étaient célibataires,
étaient célibataires,
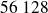 étaient mariées,
étaient mariées,
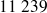 étaient veuves et
étaient veuves et
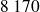 étaient divorcées.
étaient divorcées.
Distribution observée (univariée) – D.O.1 – des effectifs et des fréquences
Etant donné l'ordre de grandeur des effectifs observés, il est certainement plus « parlant » de s'exprimer en termes de « proportions (ou pourcentages) de femmes » plutôt qu'en termes de « nombres de femmes ». On est ainsi amené à présenter les données sous la forme de la distribution observée (D.O.1) des fréquences, dans laquelle on associe à chaque modalité de la variable « état civil » la proportion de femmes chez lesquelles on a observé cette modalité.
femmes parmi les
femmes interrogées étaient célibataires ; la proportion de femmes célibataires dans l'échantillon est ainsi de
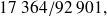 soit
soit
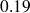 ou encore
ou encore
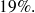 On observe également que
On observe également que
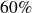 des femmes interrogées étaient mariées,
des femmes interrogées étaient mariées,
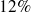 étaient veuves et
étaient veuves et
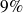 étaient divorcées.
étaient divorcées.
Exemple : Avis pédagogiques
Vingt étudiants d'une université ont été amenés à émettre un avis pédagogique sur un enseignant selon une échelle ordinale à 5 modalités : très défavorable (TD), défavorable (D), moyen (M), favorable (F), très favorable (TF).
Série statistique (
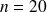 )
)
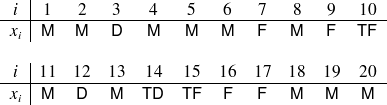
La liste brute des 20 avis constitue la série statistique observée : on y voit que les deux premiers étudiants interrogés ont émis un avis « moyen », le 3e étudiant a émis un avis « défavorable », etc. Les étudiants n° 10 et 15 ont émis un avis « très favorable » alors que l'étudiant n° 14 a émis un avis « très défavorable ».
Nous pouvons, de manière naturelle, réorganiser ces données et les présenter sous la forme d'une distribution observée (ou D.O.1). Il suffit d'associer à chacune des 5 modalités d'avis l'effectif qui lui correspond, c'est-à-dire le nombre d'étudiants qui ont indiqué cette modalité de réponse, ainsi que la fréquence qui lui correspond, c'est-à-dire la proportion ou le pourcentage d'étudiants qui ont donné cette modalité de réponse.
Distribution observée (D.O.1) des effectifs et des fréquences
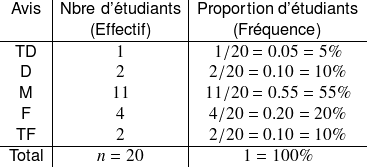
On constate ainsi, par exemple, que 11 des 20 étudiants, soit 55% des étudiants, ont émis un avis « moyen » : l'effectif associé à la modalité « moyen » est égal à 11 et la fréquence associée à cette modalité est égale à 55%. Seulement 2 des 20 étudiants, soit 10% des étudiants, ont émis un avis « très favorable » : à cette modalité de réponse sont donc associés un effectif égal à 2 et une fréquence égale à 10%.
Il va de soi que la somme des effectifs associés aux différentes modalités de la variable « Avis pédagogique » doit être égale à 20, le nombre total d'étudiants interrogés, et que la somme des fréquences doit être égale à 1 ou, de manière équivalente, à 100%.
Exemple : Personnes à charge
L'assistant social d'un Centre Public d'Aide Sociale s'est intéressé au nombre de personnes à charge parmi les ayants-droit demandeurs d'assistance. Il a sélectionné au hasard 100 dossiers et a relevé, dans chacun d'eux, le nombre de personnes à charge déclarées.
Série statistique (
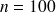 )
)

La liste brute des nombres de personnes à charge relevés dans les 100 dossiers constitue la série statistique observée : le 1er dossier indiquait une seule personne à charge, le 2e dossier en indiquait 2, le 3e dossier en indiquait 3, le 4e dossier n'indiquait aucune personne à charge, etc.
Le tableau de la distribution observée réorganise les données de manière naturelle et les présente de manière plus claire, sans pour autant nous faire perdre la moindre information contenue dans la série statistique de départ.
Distribution observée (D.O.1) des effectifs et des fréquences
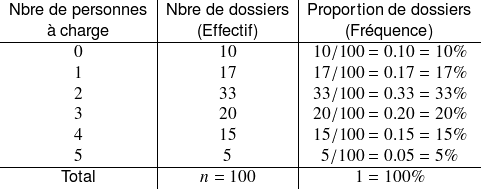
La première colonne dresse la liste des différentes valeurs observées pour la variable « nombre de personnes à charge », rangées par ordre croissant : ces valeurs varient de 0 à 5.
Les 2e et 3e colonnes présentent respectivement les effectifs et les fréquences associés aux différentes valeurs observées pour la variable « nombre de personnes à charge » : dans 10 des 100 dossiers étudiés, autrement dit dans 10% des dossiers étudiés, aucune personne à charge n'était déclarée ; dans 17 des 100 dossiers étudiés, autrement dit dans 17% des dossiers étudiés, une seule personne à charge était déclarée ; etc.
Définition :
Une distribution observée à une dimension (que nous noterons plus brièvement par D.O.1) est définie par les valeurs (ou modalités) distinctes qui apparaissent dans la série observée (ou la série ordonnée) et le nombre de fois que chacune d'elles apparaît (effectif). On peut compléter cette réorganisation des données en calculant la fréquence de chaque valeur (ou modalité) distincte observée, c'est-à-dire la proportion d'observations de la série observée (ou ordonnée) qui sont égales à cette valeur (ou modalité).
Complément : Notations utilisées pour définir une D.O.1
Les notations nous permettant de définir une D.O.1 de façon formelle sont les suivantes :
on désigne par
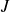 le nombre de valeurs (ou modalités) distinctes observées ;
le nombre de valeurs (ou modalités) distinctes observées ; chacune de celles-ci est représentée par la notation
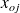 , où
, où
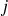 est un nombre entier compris entre
est un nombre entier compris entre
 et
(la lettre
et
(la lettre
 rappelle le nom de la variable ; l'indice
est précédé par la lettre
rappelle le nom de la variable ; l'indice
est précédé par la lettre
 – première lettre du mot « observé » – de manière à bien faire la distinction entre la valeur observée
et l'observation (ou la donnée)
– première lettre du mot « observé » – de manière à bien faire la distinction entre la valeur observée
et l'observation (ou la donnée)
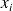 de la série statistique observée) ;
de la série statistique observée) ; l'effectif associé à la valeur
, c'est-à-dire le nombre de fois que cette valeur apparaît dans la série observée, est noté
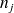 ;
; la fréquence associée à la valeur
, c'est-à-dire la proportion d'observations de la série statistique égales à cette valeur, est notée
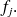
La distribution observée (D.O.1) des effectifs qui résulte de la série statistique observée (ou ordonnée) est alors définie par l'ensemble des couples
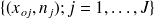 ; la D.O.1 des fréquences est définie par l'ensemble des couples
; la D.O.1 des fréquences est définie par l'ensemble des couples
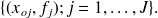
La D.O.1 est généralement présentée sous la forme d'un tableau :

Remarque :
Si la variable
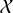 est ordinale ou quantitative (d'intervalles ou de rapports), il est pratique de présenter les valeurs ou modalités distinctes observées
est ordinale ou quantitative (d'intervalles ou de rapports), il est pratique de présenter les valeurs ou modalités distinctes observées
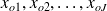 rangées par ordre croissant.
rangées par ordre croissant.
Fondamental : Différence entre n et J
Il est important de ne pas confondre
 (le nombre d'observations dans la série statistique observée ou ordonnée) et
(le nombre de valeurs/modalités distinctes rencontrées dans cette série statistique).
(le nombre d'observations dans la série statistique observée ou ordonnée) et
(le nombre de valeurs/modalités distinctes rencontrées dans cette série statistique).
Dans l'exemple relatif à l'enquête menée auprès de femmes (exemple « Femmes »),
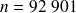 (nombre de femmes interrogées) et
(nombre de femmes interrogées) et
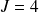 (nombre de modalités de la variable « état civil »).
(nombre de modalités de la variable « état civil »).
Dans l'exemple relatif aux avis pédagogiques donnés par des étudiants sur un enseignant (exemple « Avis pédagogique »),
(nombre d'étudiants interrogés) et
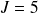 (nombre de modalités de la variable « avis »).
(nombre de modalités de la variable « avis »).
Dans l'exemple relatif aux nombres de personnes à charge relevées dans des dossiers d'un CPAS (exemple « Personnes à charge »),
(nombre de dossiers étudiés) et
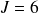 (nombre de valeurs distinctes observées pour la variable « nombre de personnes à charge »).
(nombre de valeurs distinctes observées pour la variable « nombre de personnes à charge »).




